Why Your AI Eval Framework Fails After Deployment
Your AI passed every test you designed—which is exactly the problem. A framework built to protect your launch record won't keep agents sharp when reality shows up swinging.

Your Eval Framework Passed the Model. It Did Not Survive the Deployment.
Evaluation frameworks are launch gates. Harness maintenance is what keeps agents useful after they go live.
In Rocky III, Mickey curated the fights. Rocky had the belt, the fame, the training facility, and the montage. What he did not have was an opponent who could actually test him. Mickey knew it. He built a program designed to protect Rocky's record, not to keep Rocky sharp. When Clubber Lang arrived, Rocky lost badly, and the reason was not a lack of talent. The reason was that the preparation system had been optimized for a winning percentage, not for readiness.
That gap between a protected record and actual readiness is the same gap most enterprise AI programs have between their evaluation frameworks and their deployed agents. The eval passed. The model shipped. The record looks clean. Nobody scheduled the rematch preparation.
The industry's default behavior is to treat LLM evaluation as a launch gate. Build the benchmark suite, pass the thresholds, ship the agent. McKinsey's 2024 AI survey found that 65% of organizations now regularly use generative AI, up from 33% the year before. Databricks research documents that evaluation and testing infrastructure lags deployment maturity by 12 to 18 months. The agents are live. The harnesses are not keeping up. That is a structural problem, and it does not get solved by adding more tools to the pre-launch checklist.
The Evaluation Pyramid Is Not a Launch Checklist
Taylor Jordan Smith, an AI developer advocate at Red Hat, organized LLM evaluation into a three-tier structure at an AI engineering conference workshop this year. The base layer is system performance: throughput, latency, concurrent request handling, GPU utilization. No matter how accurate the model is, if it cannot serve traffic reliably and affordably, the program has a foundational problem. The middle layer is factual accuracy and output format: does the model produce correct answers on the tasks it is deployed to perform, and does it return output in the format the application expects? The top layer is safety, bias, and custom domain evaluation: does the model behave within the guardrails the organization has committed to, and does it perform correctly on scenarios specific to the use case?
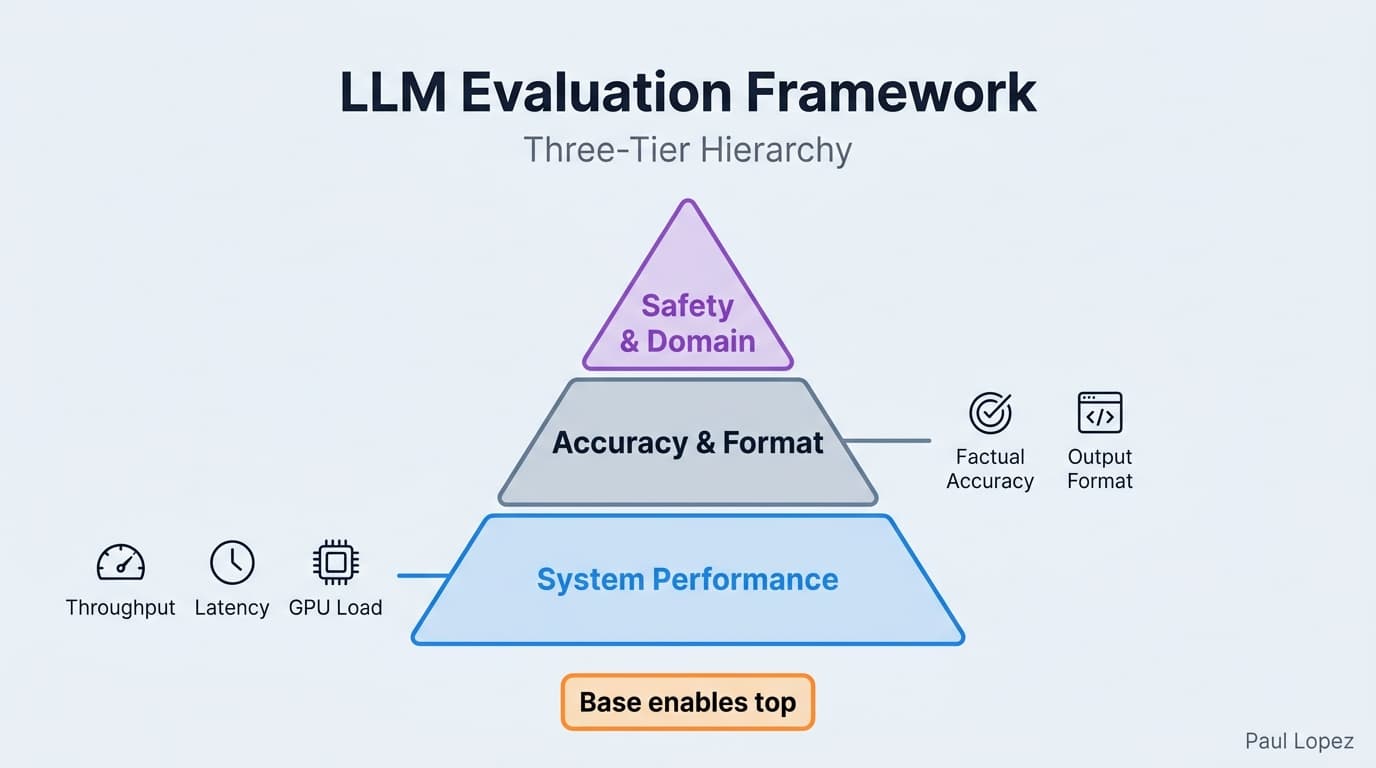
The pyramid structure is sound. What is missing from it is a time dimension. Every layer of the pyramid needs to be re-evaluated continuously, not once at launch. System performance changes as request volume scales, as inference runtime versions update, and as model sizes shift. Factual accuracy changes as the model is updated or replaced. Safety posture changes as the organization's risk tolerance evolves and as adversarial prompting techniques improve. A pyramid that is evaluated once at launch and then declared stable is not a quality framework. It is a snapshot of what was true on a particular day.
Enterprises take an incremental approach to evaluation coverage, and that is correct. Start with the base layer. Add the middle layer as the deployment scales. Add the top layer as the stakes increase. But incremental coverage is not the same as continuous coverage. An evaluation that runs once per layer, at launch, and is not scheduled for recurrence has already started to expire.
Open tooling exists at each tier for teams ready to treat evaluation as a repeating obligation. GuideLLM, developed by Neural Magic and now backed by Red Hat, handles the base layer: sweep-based latency and throughput measurement for LLM serving infrastructure. EleutherAI's lm-evaluation-harness, paired with the MMLU-Pro benchmark suite, covers the middle layer with rigorous accuracy testing across 57 subject domains. PromptFoo addresses the top layer, running custom safety evals, red-team tests, and regression checks against application-layer behavior, with CI/CD integration that makes continuous execution possible. These are examples of what open tooling looks like at each tier, not an exhaustive inventory.
The Harness Is a Living System
One practitioner framing from the 2026 agent discourse makes an argument that enterprise AI architects need to hear: agents do not break only when the model gets worse. They break when the model gets better. A harness built to constrain an unreliable model can trap a more capable one. A tool that helped a weaker model navigate an ambiguous task can confuse a stronger model that no longer needs the scaffold. An approval gate that made sense when the agent made frequent errors can create drag when the agent is now right ninety percent of the time. These are not theoretical problems. They are happening in deployed agent systems today.
The Vercel sales agent example makes this concrete. The team studied a top-performing sales representative, built an agent around the observed workflow (filtering, qualifying, researching, drafting, routing), kept a human in the review loop, and deployed it. The agent worked. Then the team kept adding tools. The agent got worse. When they removed eighty percent of the tools, performance improved. The lesson is not about context window management, though that matters. The lesson is about what happens when you conflate "more capability available" with "more capability needed." A capable agent with a cluttered harness is not more powerful. It is less reliable.
The same principle governs evaluation frameworks. An eval suite built for a specific model version, against a specific set of benchmarks, measuring a specific set of behaviors, is correct for that moment. When the model version changes, the eval suite may be measuring the wrong things. When the agent's scope expands, the eval suite may be missing entire failure categories. When the business process the agent supports changes, the eval suite may be testing against a workflow that no longer exists.
A static eval suite against a dynamic harness is not quality assurance. It is false assurance. The pyramid is not a launch checklist. It is a continuous operating obligation, and every change to the harness triggers a corresponding obligation to review what the eval suite is actually measuring.
Four Failure Modes That Recur in Production
Four failure modes recur across deployed enterprise agent systems.
World drift is the most common failure mode. The agent continues to operate faithfully against instructions and context that are no longer accurate. The process it was built to automate has changed. The policy store it reads is three versions behind. The routing rules reflect last quarter's team structure. The agent does not fail loudly. It produces confident-looking output from stale inputs, and the organization inherits the cost of that confidence.
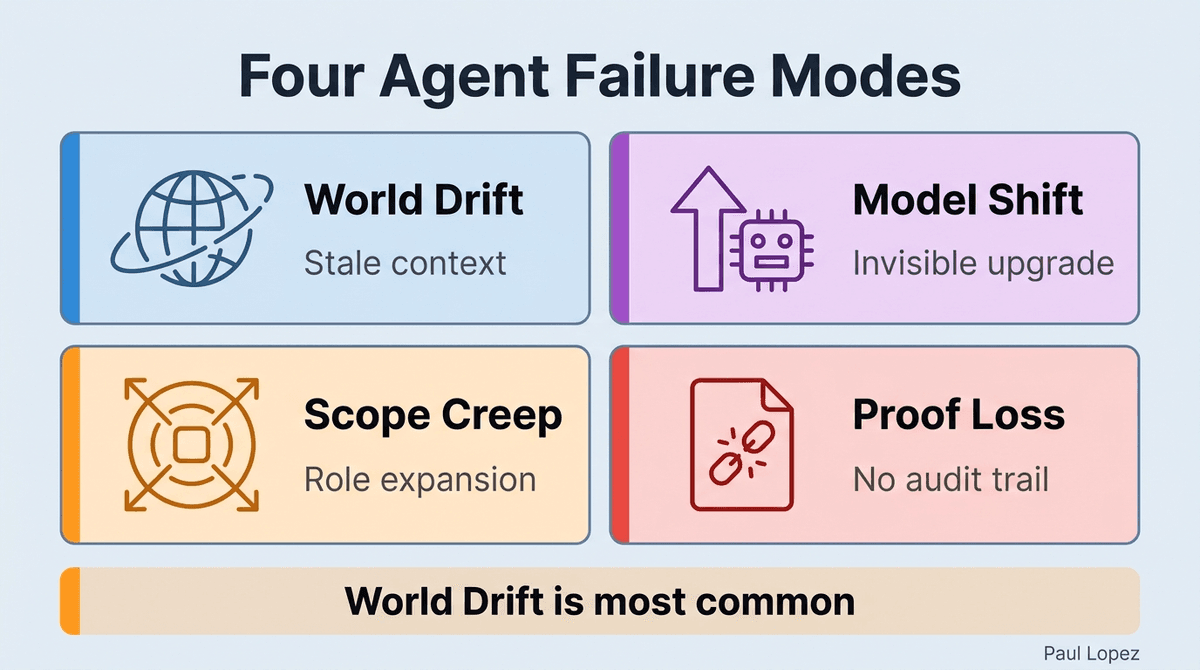
Model improvement is the failure mode that most teams do not have a mental model for. When the underlying model is updated, the harness may become wrong in either direction: a permission that was safe for a weaker model may be too broad for a stronger one that can now execute twenty plausible actions in minutes, and a restriction that protected the organization from an unreliable model may now be suppressing correct behavior that the better model is fully capable of producing. Both are real. Both require harness re-evaluation at the moment of model change, not the next quarterly review.
Scope creep is the third failure mode. Agents that start as summarizers get quietly tasked with recommendations. Agents that start with read-only access get given draft-and-submit permissions. The job changes, but the eval suite tests the original job. The organization is now evaluating an agent against a specification it abandoned six months ago.
The fourth failure mode is proof degradation. The agent's outputs stop including citations, source links, or the audit trail that makes human review meaningful. The output looks correct. It may be correct. But the human-in-the-loop has no way to verify it in the time available, so review becomes rubber-stamping, and the governance layer becomes theater.
The Small Team Objection Is Real, and It Has an Answer
This argument lands differently for a team with one ML engineer and a constrained budget than it does for an organization running a dedicated MLOps function. The honest answer is that full-coverage harness maintenance is not always achievable, and claiming otherwise would be misleading.
The pyramid helps here. Teams that cannot resource continuous evaluation across all three tiers should resource the base layer continuously and schedule the upper tiers deliberately. System performance is the easiest tier to automate: GuideLLM-class tooling runs unattended and produces structured output. A quarterly MMLU-class accuracy run takes a few hours of compute and one engineer's attention. Safety and custom evals are the most resource-intensive tier and the most appropriate to defer until the deployment scale justifies them.
The goal is not maximum coverage. The goal is honest coverage: knowing what is and is not being evaluated, having a plan for when each tier will be re-evaluated, and treating the harness maintenance schedule as an architectural decision rather than an afterthought. A team that knows its eval suite is six months stale and has a date to refresh it is in a better position than a team that believes its six-month-old eval suite is still current.
The incremental path Smith described at the workshop applies here directly. For a RAG deployment, a small team starts with retrieval component evaluation: are the right documents being retrieved? Then adds latency benchmarking as traffic grows. Then builds toward full system evaluation as the deployment matures and stakes increase. That sequence is the small team roadmap. Each tier added is a permanent addition to the evaluation calendar, not a one-time event.
Five Checks for the Next Harness Review
Five checks are worth running at any scheduled harness review interval, whether that is monthly, quarterly, or triggered by a model version change.
First, what is the agent reading? Are the sources current? Did a process change that invalidated a document the agent treats as policy? Did a new source become authoritative that the agent does not have access to?

Second, what can the agent touch? The permission set that was appropriate at launch may be too narrow for a better model or too broad for an expanded scope. Neither is automatically correct. Review it explicitly.
Third, is the job still the same? If the agent was scoped as a summarizer and is now being asked to recommend, the eval suite needs to be rebuilt for the new job, not patched.
Fourth, what proof is the agent required to bring back? Output that cannot be traced to a source is output that cannot be reviewed. The human-in-the-loop checkpoint is only meaningful if the agent is required to show its work.
Fifth, is the agent still delivering value? This one is the most avoided. When the model improves, the right question is sometimes whether the agent should be rebuilt around the new model's capabilities. When the business changes, the right question is sometimes whether the agent should be retired.
The training montage is not what makes a fighter ready for the next fight. A controlled record built against selected opponents is not readiness. What makes the difference is whether the preparation regimen is calibrated to what the next opponent actually requires. The same logic applies to agents in production. Evaluate honestly. Schedule it. Rebuild the harness when the fight changes. The goal is not a winning record in controlled evaluation conditions. The goal is a harness that keeps the agent ready for the opponent it has not yet seen.
References
[1] Neural Magic. "GuideLLM: Evaluate and optimize LLM deployments." GitHub, 2024. https://github.com/neuralmagic/guidellm
[2] Red Hat. "Red Hat Acquires Neural Magic to Accelerate AI Inference." Red Hat Newsroom, 2024. https://www.redhat.com/en/about/press-releases/red-hat-acquires-neural-magic
[3] Gao, L., et al. "A Framework for Few-Shot Language Model Evaluation." EleutherAI. GitHub, 2021, updated 2024. https://github.com/EleutherAI/lm-evaluation-harness
[4] Wang, Y., et al. "MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark." arXiv:2406.01574, 2024. https://arxiv.org/abs/2406.01574
[5] Webster, I. and Klopfer, M. "PromptFoo: Test your LLM app." GitHub, 2024. https://github.com/promptfoo/promptfoo
[6] PromptFoo Documentation. "CI/CD Integration." 2024. https://www.promptfoo.dev/docs/integrations/ci-cd/
[7] Gartner. "Hype Cycle for Artificial Intelligence, 2024." Gartner Research, 2024.
[8] DORA. "Accelerate State of DevOps Report." Google Cloud, 2023. https://cloud.google.com/devops/state-of-devops/
[9] Andreessen Horowitz. "The State of AI in the Enterprise." a16z, 2024. https://a16z.com/ai-enterprise-2024/
[10] Husain, H. "Your AI Product Needs Evals." Hamel's Blog, 2024. https://hamel.dev/blog/posts/evals/
[11] MLOps Community. "LLM in Production Survey." 2024. https://mlops.community/
[12] Databricks. "State of Data + AI Report." 2024. https://www.databricks.com/resources/analyst-paper/state-of-data-ai
[13] McKinsey and Company. "The State of AI in 2024: GenAI's Breakout Year." 2024. https://www.mckinsey.com/capabilities/quantumblack/our-insights/the-state-of-ai
[14] LangChain. "State of AI Agents." 2024. https://www.langchain.com/stateofaiagents
[15] OpenAI Developer Forum. "GPT-4 behavior changes after November update." Multiple threads, 2023. https://community.openai.com/
[16] Willison, S. "LLM eval and model version changes." simonwillison.net, 2024. https://simonwillison.net/