Hallucinations Cannot Survive When Evidence Comes First
Evidence-first AI that kills hallucinations before they breathe—built for prior auth justifications where a fabricated clinical fact doesn't just fail, it costs patients care.

The Sentence That Cannot Be Said Without Proof
A design postmortem on fhir-prior-auth-copilot, and why the right place to stop a hallucination is before generation, not after.
Harvey Specter does not wing it. If you watched Suits, you know the rule he drills into Mike Ross from the beginning: never ask a question you do not already know the answer to. That rule is not a courtroom trick. It is a preparation philosophy. Harvey walks into a deposition already knowing every answer the witness will give, because he has already verified every piece of evidence, anticipated every counterargument, and mapped every angle before the proceeding begins. The courtroom is not where he builds his case. It is where he presents the case he already built.
His preparation is the work. Everything else is just the public performance of it. When Harvey discovers during prep that a piece of evidence will not hold up under cross-examination, he drops it from his argument rather than hoping opposing counsel will not notice. He does not improvise in front of the judge and trust his instincts to carry him through a gap in the evidence. He does not submit a claim he cannot back up, because the cost of submitting an unsubstantiated claim is not just losing that argument. It is losing credibility for everything that follows.
A prior authorization justification submitted to a payer is making factual claims about a patient's clinical record in exactly the same way courtroom testimony makes factual claims about evidence. The staff writing these justifications are not clinicians reviewing the chart in detail, are not paid to read 500-page payer policy documents, and under time pressure write generic language that gets requests denied for insufficient documentation. The denial is frequently self-inflicted: not because the care was inappropriate, but because the written justification did not connect the documented clinical facts to the payer's stated criteria clearly enough for the reviewer to find them. The fix is not a better appeals process. It is writing the correct justification the first time, by verifying what the clinical record actually supports before committing a single sentence to paper.
What This Prototype Does
The software terms in this article reference the server code at github.com/paullopez-ai/fhir-prior-auth-copilot.
fhir-prior-auth-copilot reads a patient's FHIR R4 record and produces a prior authorization justification where every claim traces to a specific FHIR resource by type and id. A payer reviewer, or an automated payer system, can verify each claim against the source data directly instead of taking the narrative on faith. This is the standards-layer version of Harvey's preparation discipline: every sentence in the output has its foundation established before it is written, and the evidence trail is machine-verifiable.
All patient data in this build is synthetic, generated with Synthea, and no real patient records were used at any point.
The Decision to Map Criteria Before Writing a Word
The system separates two questions that most AI-generated documentation collapses into one. The first question is: what does this patient's record actually support? The second question is: how do I phrase that persuasively? Most approaches let a language model answer both at once, which means the model is free to write a fluent sentence about a criterion the record never actually satisfied.
This prototype answers the first question entirely in code, before a prompt is written. The Criteria Mapper Node evaluates each payer criterion against the bundle using a typed specification, and separately calls clinical-rules-mcp-server for the criteria that actually apply to this patient's diagnosis and requested service. Only after that mapping is complete does the Justification Generator Node receive a list of which criteria are citable.
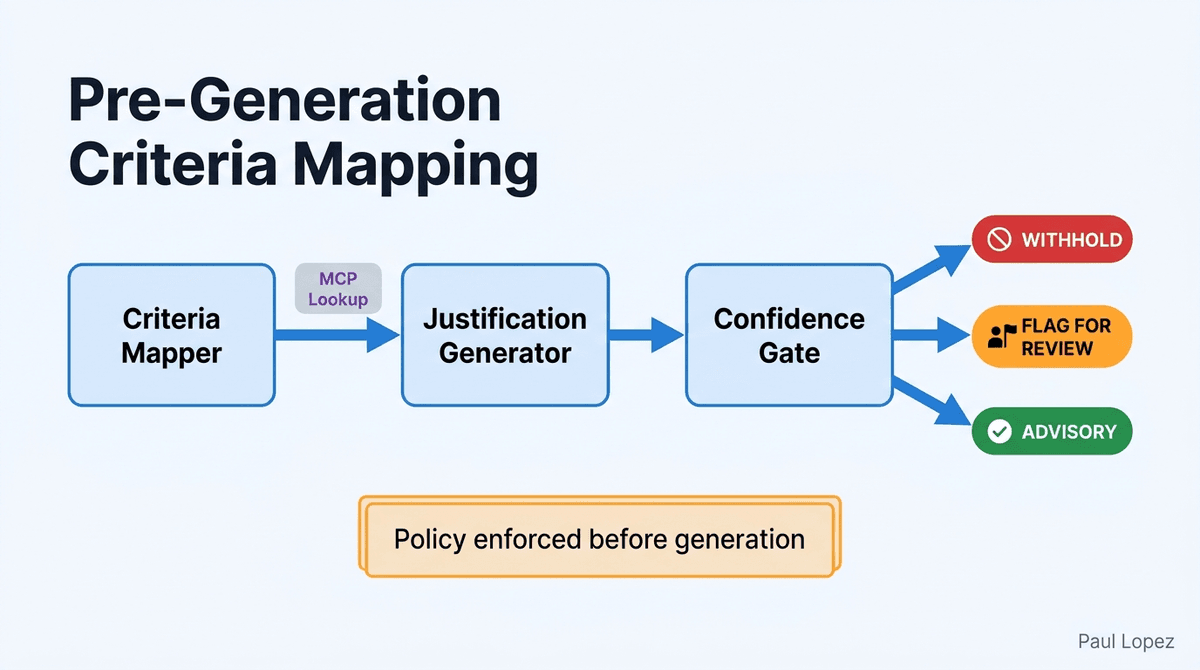
It writes language for what was already determined to be supportable. It never decides on its own what counts as sufficient evidence.
The mechanism lives in src/spec.py. Each CriterionSpec entry pins the exact FHIR resource type and field path for the criterion it governs, and names a MissingFieldPolicy that decides what happens when a required field is absent or ambiguous. The three policies are WITHHOLD (the sentence is never generated), FLAG_FOR_REVIEW (the case routes to a human reviewer), and ADVISORY (the gap is recorded but does not block or withhold output). There is no fourth, implicit branch where the model improvises around a missing field. The spec module imports no LLM client, and the module's own docstring states that explicitly. This is a deliberate ordering choice: criteria mapping happens before narrative generation so the system knows what it is allowed to claim before it starts writing.
The LangGraph pipeline in graph.py wires the three nodes in sequence: Criteria Mapper, Justification Generator, Confidence Gate. If LangGraph is unavailable, the same three nodes run as a plain function pipeline with identical ordering, so the system never silently degrades the sequence regardless of the execution environment.
The Sentence That Never Gets Written
Most AI guardrail designs work the same way: generate freely, then run a check that catches the bad output before it ships. That ordering means an unsupported claim exists, briefly, inside the system. Something had to generate it before something else could catch it.
The Justification Generator Node in this prototype does not work that way. It receives only the criterion keys already determined to be citable. It emits a sentence only for a criterion that has already resolved to a citable FHIR resource. A criterion with no citation is not generated and then deleted; it is never generated at all.
The withheld criteria, the blocking gaps, and the advisory gaps are tracked separately. Each is routed according to the policy named in the specification, not discovered by a quality check after the fact.
Scenario 2 in the walkthrough guide is the clearest proof point. The patient's Condition resource has no documented severity field, so condition_severity is not citable under its WITHHOLD policy. The system never generates a sentence asserting severity. The case routes to the human review queue, and the review queue entry persists to SQLite with the exact criterion name that triggered the routing. The audit trail names the missing field, not a generic "low confidence" label. A reviewer opening that queue entry knows precisely what to look for in the chart before they can resubmit.
This is the architectural difference that matters: confidence is not a score bolted onto a finished LLM output and used to guess whether the output is safe to ship. The Confidence Gate Node computes confidence as the ratio of cited required criteria over total required criteria, an auditable number computed from the same CriterionMatch data that the Criteria Mapper already produced. In Scenario 1, where every required criterion is satisfied, confidence resolves to 1.0 and six cited sentences ship. In Scenario 2, where condition_severity is missing, the ratio drops below threshold and the case routes. The confidence number is never an LLM self-report. The LLM did not generate it, and the LLM cannot inflate it.
Retrieving Only What This Patient's Case Needs
Payer policy criteria do not need to live inside every prompt. The system retrieves only the criteria relevant to the patient's actual diagnosis and requested service, by calling clinical-rules-mcp-server's existing tool surface, rather than pasting an entire policy document into the context window and hoping the model finds the right paragraph.
The mechanism is concrete. The Criteria Mapper Node calls check_auth_requirements and flag_documentation_gaps via Streamable HTTP, passing the patient's specific clinical facts translated from FHIR fields into each tool's typed input contract. The procedure code comes from the ServiceRequest CPT coding. The diagnosis group comes from ICD-10 family lookup. The plan type comes from Coverage.type.coding.code. The payer id comes from the Coverage.payor reference. The MCP server receives structured inputs, not a summary paragraph.
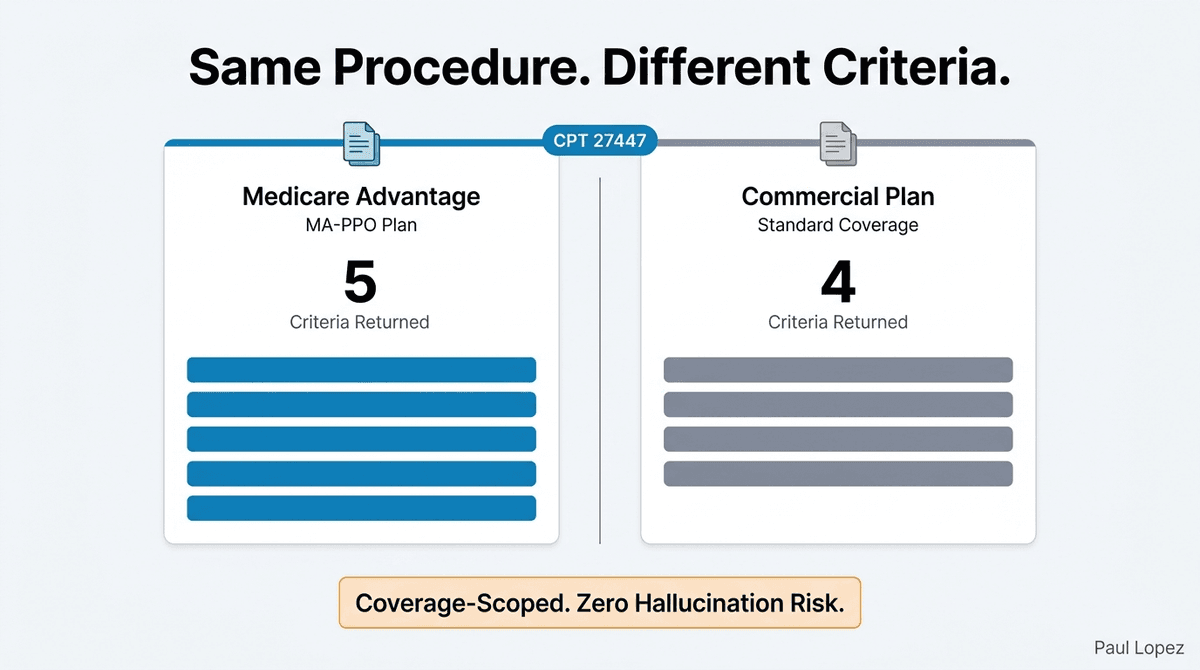
Scenario 3 in the walkthrough guide shows why scoping matters in practice. The same procedure, CPT 27447 (total knee arthroplasty), evaluated under a Medicare Advantage plan (PAYER_MEDICARE_ADV_B, plan type MA-PPO) returns a five-criteria set. The same procedure under a commercial plan returns four. The difference is not a configuration toggle. It is retrieval scoped to the actual Coverage resource in the patient's bundle, not a blanket policy dump applied to all requests. A hallucinated criterion cannot enter the pipeline through this path, because the only criteria the Justification Generator ever sees are the ones the MCP server returned for this specific patient's coverage.
This prototype is a direct downstream consumer of clinical-rules-mcp-server's check_auth_requirements and flag_documentation_gaps tool surface. Readers who want the design postmortem on that server itself, including how its rules engine is structured and how it handles criteria versioning, can find it in "Mapping the Territory: Why Official Roads Need Community Knowledge".
What Happens When the Dependency Is Down
The MCP server is an independently deployed service, and the system has a named answer for what happens if it is unreachable. With MCP_FALLBACK_FIXTURES=true (the default), the Criteria Mapper falls back to a deterministic fixture dataset and records source="fallback-fixture" on the result. The downstream pipeline continues, and the audit trail marks every criterion resolved against the fixture rather than a live server call. No output is produced without the operator knowing which data source it came from.
If the operator wants a loud failure instead, setting MCP_FALLBACK_FIXTURES=false forces a named MCPUnreachableError. The pipeline stops. Nothing ships. This is the same discipline applied to an infrastructure failure that the system applies to a missing clinical fact: a named outcome for the gap, not a silent substitution that looks like a successful run.
The same logic applies to malformed input. Scenario 4 in the walkthrough guide submits a bundle with a dangling Patient reference (Patient/pat-DOES-NOT-EXIST). The FHIR loader validates through fhir.resources Pydantic models, the bundle fails at parse time with HTTP 422 and a named error, and the orchestration pipeline never starts. Invalid data is caught before generation begins, not discovered mid-output when a sentence about a non-existent patient would already be in the draft. The system does not attempt to interpret what the caller probably meant. It rejects the input and names the problem.
What This Prototype Does Not Solve
This build runs against curated synthetic Synthea bundles checked into the repository. There is no live connection to a production FHIR server such as Epic or Cerner, no SMART on FHIR authentication, and no HIPAA-compliant data handling layer. The payer policy criteria in the demo are illustrative and synthetic. They are not drawn from any actual payer's published policy documents, and using them as a compliance reference would be a mistake.
The live LLM path runs against the OpenAI API directly, using gpt-5.4 by default. An Azure OpenAI migration is a configuration change rather than an architecture change, because the LLM client interface is already written against the OpenAI-compatible chat completion schema. A production deployment would also need centralized secrets management (Azure Key Vault or equivalent) instead of local .env files, an ongoing evaluation harness beyond the golden dataset used here (Azure AI Foundry or equivalent), and Terraform IaC for any hosted deployment target. There is no hyperscaler-hosted track implemented in this build.
None of this reflects a flaw in the architectural choices. The decisions that matter here, criteria evaluation before generation, auditable confidence computed from the same match data, named failure modes for every gap and infrastructure fault, would carry forward unchanged into a production system. What changes between this postmortem and an enterprise deployment is the data source, the authentication layer, and the infrastructure underneath them. The ordering of operations does not change, because the ordering of operations is the point.
Close
Harvey Specter would not submit a justification he could not back up with evidence from the chart, and this system is built so that nobody else can either.
The discipline that matters here is not a smarter model. It is deciding, in code, what counts as proof, before any sentence gets a chance to sound confident about something it cannot support.
Prior authorization justifications fail reviews not because the underlying care was wrong, but because the written case never connected the documented facts to the criteria clearly enough for a reviewer to verify them. This prototype treats that as a sequencing problem, not a language problem. Fix the sequence, and the language follows the evidence rather than inventing it.
If you are building in the prior authorization or clinical documentation space and you want to compare notes on the design, the repository is open. And if you are curious about how these FHIR-native agent patterns extend into ambient, always-on workflows, the sibling prototype prior-auth-ambient-agent covers that territory, explored in "When the Agent Wakes Up on Its Own".
References
[1] Centers for Medicare & Medicaid Services. "Interoperability and Prior Authorization Final Rule (CMS-0057-F)." Federal Register, January 17, 2024. https://www.federalregister.gov/documents/2024/02/08/2024-00895/medicare-and-medicaid-programs-patient-protection-and-affordable-care-act-advancing-interoperability
[2] Centers for Medicare & Medicaid Services. "CMS-0057-F Fact Sheet and FAQ: Prior Authorization API Requirements." CMS.gov, 2024. https://www.cms.gov/newsroom/fact-sheets/interoperability-and-prior-authorization-final-rule-cms-0057-f
[3] American Medical Association. "2024 AMA Prior Authorization Physician Survey." AMA, February 2025. https://www.ama-assn.org/system/files/prior-authorization-survey.pdf
[4] CAQH. "2023 CAQH Index: Conducting Electronic Business Transactions." CAQH, 2024. https://www.caqh.org/insights/caqh-index
[5] Centers for Medicare & Medicaid Services. "Marketplace Oversight: Prior Authorization Data Analysis, Plan Year 2022." CMS.gov, 2023. https://www.cms.gov/marketplace/about/oversight
[6] HL7 Da Vinci Project. "Da Vinci Prior Authorization Support (PAS), Coverage Requirements Discovery (CRD), and Documentation Templates and Rules (DTR) Implementation Guides." HL7.org, 2024-2025. https://www.hl7.org/about/davinci/