XGBoost Beats GPT for Hospital Readmission Risk Prediction
Choosing the right AI is like Moneyball: it's not about the flashiest tool, but the one that actually wins games—and saves lives.
The Model That Does Not Hallucinate: When XGBoost and SHAP Beat GPT for Clinical Risk Scoring
Billy Beane's insight was not that statistical analysis was new to baseball. It was that the baseball community was measuring the wrong things. Batting average and stolen bases were the impressive-looking metrics everyone understood. On-base percentage and slugging were the metrics that actually predicted runs, and therefore wins. The Oakland A's competed with a $44M payroll against teams spending three times that because they had the discipline to use the right model for the specific prediction problem in front of them.
The enterprise AI equivalent: organizations are reaching for large language models because they are impressive and because everyone understands what they do. The right question is not "can an LLM do this?" The answer to that question is almost always yes. The right question is "what is the best-calibrated model for this specific prediction task, and what does it cost per prediction to be wrong?" For 30-day hospital readmission risk, the answer is XGBoost with SHAP explainability and a committed calibration benchmark. Not because GPT cannot score a discharge record. Because XGBoost produces a calibrated probability in 15 milliseconds (server-side inference is under 15ms) with feature-level attribution that a clinical informaticist can audit.
The readmission-risk-scorer prototype was built on exactly this reasoning. The problem was 30-day hospital readmission prediction at discharge. The right model was not GPT-5. It was XGBoost.
CMS has penalized hospitals up to 3% of Medicare DRG payments for excess readmissions since 2013. Every discharge is a decision point: which patients need intensive care coordination, and which can follow a standard protocol? That decision, made incorrectly at scale, has a direct line to financial penalty and patient harm. It deserves a model selected for that specific decision, not the most impressive model available.
What This Prototype Does
The system performs 30-day readmission risk scoring using XGBoost classification with under 15ms inference per discharge record, SHAP feature-level attribution, three risk tiers (High, Moderate, Low) with configurable thresholds, human review queue for high-risk patients before any care coordination action is triggered, and a committed ROI model that compares inference cost against avoided CMS penalties. The complete implementation is available at github.com/paullopez-ai/readmission-risk-scorer.
The Decision Not to Use a Language Model
The most important design decision in this prototype is not which features to include or how to tune the XGBoost hyperparameters. It is the decision to keep a language model out of the prediction path entirely.
This is not an anti-LLM argument. LLMs are the right tool for a wide range of clinical AI problems, and several other prototypes in this series use Claude or GPT directly in the decision path. But 30-day readmission risk prediction is a classification problem with a specific output requirement: a calibrated probability, produced quickly, with auditable feature attribution.
An LLM can produce a readmission risk assessment. It will sound authoritative. It will cite relevant clinical factors. It will be wrong at a rate that is difficult to measure without a formal evaluation harness, and it will not tell you what drove its conclusion in a form that a clinical informaticist can audit. It cannot be evaluated against a held-out test set with AUROC, F1, and a calibration plot. It has no concept of inference cost per prediction. And it takes one to three seconds to respond, not fifteen milliseconds.

XGBoost, paired with SHAP explainability and a rigorous evaluation harness, produces a calibrated probability in 15ms with feature-level attribution that maps directly to clinical reality: prior admissions, comorbidity index, discharge destination, and length of stay. The model is wrong sometimes. That wrongness is measurable, documented in eval-report.json, and committed to the repository so any reviewer can reproduce the benchmark.
The /predict/explain endpoint demonstrates where the LLM belongs in this architecture: as a narrative wrapper around a decision already made by XGBoost. The LLM receives the risk score, the risk tier, and the top SHAP factors, and generates a plain-language summary a clinician can share with the care coordination team. The LLM explains the decision. It does not make it. That distinction is the architecture. Prior authorization processing requires language understanding because the clinical notes, coverage criteria, and denial reasons are unstructured text; readmission risk scoring requires probability calibration because the input is structured discharge data.
SHAP Is the Responsible AI Layer
Healthcare AI explainability is often treated as a compliance checkbox: provide some explanation, satisfy the auditor, move on. SHAP is not a compliance checkbox. It is the mechanism that makes the model's reasoning auditable in clinical terms.
The SHAP global summary plot committed to reports/shap-summary.png answers the question every clinical informaticist should ask before deploying any risk model: what did the model actually learn? For a well-calibrated readmission model, prior admissions, high comorbidity index, and skilled nursing facility discharge should appear at the top of the SHAP feature importance ranking. If they do not, something is wrong with the training data, and the plot makes that visible before the model reaches a patient.
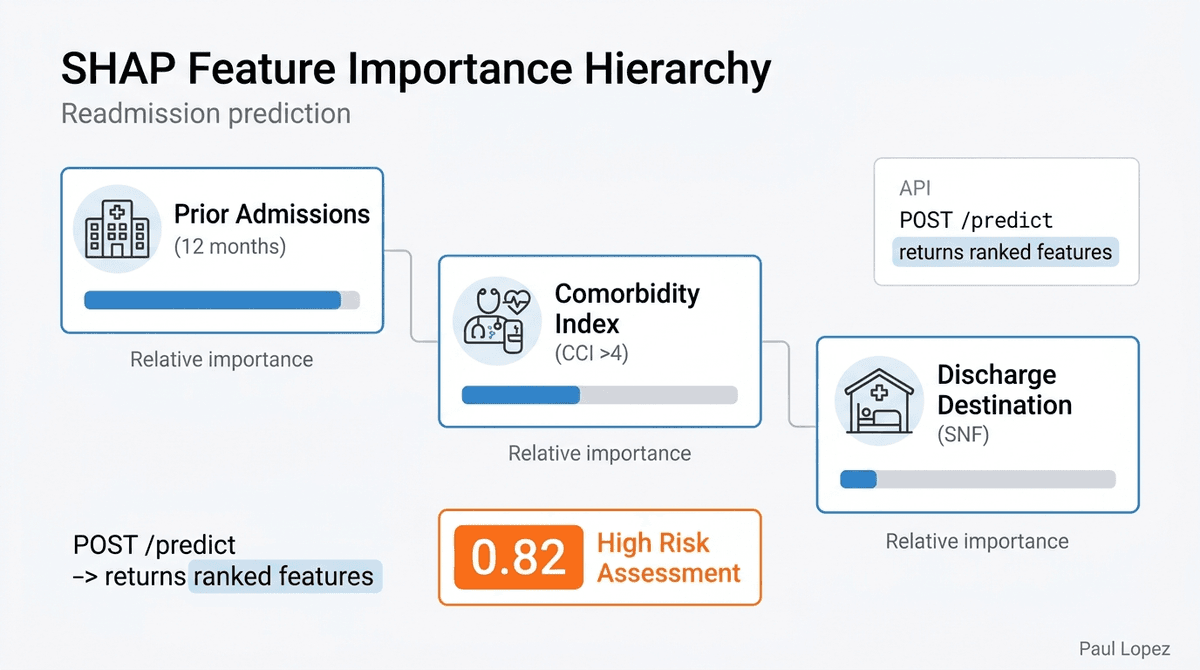
The per-prediction shap_factors[] array in the API response carries the same logic to the individual level. Every risk assessment returned by POST /predict includes the top features that drove that specific patient's score, in order of impact. A discharge planner who receives a high-risk assessment can see not just that the patient scored 0.82, but that prior admissions in the last 12 months, a Charlson Comorbidity Index above 4, and discharge to a skilled nursing facility were the three primary drivers. That is an explanation a clinical professional can act on and dispute if it is wrong.
The distinction between calibration and accuracy is worth making explicitly. AUROC measures whether the model correctly ranks patients by relative risk: does it put the higher-risk patient above the lower-risk patient? Calibration measures whether the model's probability output is trustworthy in absolute terms: if the model says 70% readmission risk, are approximately 70% of those patients actually readmitted? A model that ranks well but is poorly calibrated produces a leaderboard, not a decision tool. The calibration plot in reports/calibration-plot.png is the artifact that proves the model can be trusted at the probability level, not just the ranking level.
The Committed Benchmark and What It Signals
The trained model artifacts (models/xgb_readmission_v1.joblib, models/scaler_v1.joblib, models/feature_names.json) and the full evaluation outputs (reports/eval-report.json, reports/shap-summary.png, reports/roc-curve.png, reports/calibration-plot.png) are committed to the repository. This is a governance decision, not a storage decision.
A benchmark that exists only in a notebook that was run once, on a machine that is no longer configured the same way, against data that has since been updated, is not a benchmark. It is a historical record that cannot be disputed or reproduced. A committed benchmark is a claim: this model produces these results, against this held-out test set, and anyone who clones the repository can verify that claim by running scripts/evaluate.py.
For enterprise AI programs operating under healthcare compliance requirements, this reproducibility is not optional. Regulators, auditors, and medical directors will ask how the model was validated. "We ran it in a notebook and it looked good" is not an answer. "The held-out evaluation is committed to the repository, the benchmark is reproducible, and the calibration plot is here" is.
The Cautions Document
The repository includes cautions.md, an explicit limitations document. This is rare. Most public ML prototypes ship without one. Having it signals something specific about the architecture philosophy: the model's limitations are known, documented, and treated as first-class artifacts rather than things to be discovered in production.
Clinical AI limitations documents matter most at the deployment decision boundary. Before a risk model enters a clinical workflow, someone with accountability for patient outcomes needs to ask: what does this model not do well? Where does it fail? Under what conditions should it not be trusted? cautions.md answers those questions in advance, before the conversation with the medical director or the clinical informatics committee, not after.
The discipline of writing a limitations document before deployment also forces an honest accounting of the training data. This prototype uses synthetic data. A production deployment requires recalibration on real discharge data from the target patient population. That requirement is in cautions.md. The prototype does not hide it in a footnote or a README caveat. It is a named document with the same standing as the architecture diagram.
The ROI Model as Architecture
The API response includes a cost_usd field. Every prediction carries its own cost. At 50 discharges per day, the Azure ML managed online endpoint costs approximately $0.38/day. One prevented readmission avoids up to $15,000 in CMS penalty exposure. The math does not require a sophisticated model: even a prevention rate well below 1% produces a positive ROI. Enterprise architects who can present this kind of argument get AI programs approved. Those who cannot get them deferred.
The cost_usd field in the API response also enables a conversation that most enterprise AI programs never have: what does it cost to be wrong? A false positive (over-identifying low-risk patients as high-risk) consumes care coordination capacity unnecessarily. A false negative (missing a high-risk patient) carries the full penalty exposure. The threshold sensitivity analysis in the evaluation harness shows how precision and recall trade off across the High/Mod/Low tier boundaries. The threshold is a governed parameter, not a hardcoded constant, because the cost asymmetry between false positive and false negative is a business and clinical judgment, not a data science judgment.
What This Architecture Demonstrates for Enterprise AI Programs
The readmission-risk-scorer prototype makes a case that most enterprise AI programs need to hear: model selection is an architecture decision, not a default. The questions that should precede any AI model selection are not "what is the most capable model available?" but rather: what type of output does this problem require, and which model produces that output with the best combination of speed, calibration, explainability, and cost?
For structured clinical data with a binary outcome, that reasoning leads to XGBoost. For unstructured clinical text with a language understanding requirement, it leads to Claude or GPT. For a real-time authorization decision that needs both, it leads to a hybrid: classical ML for the risk score and an LLM for the narrative explanation. The architecture should match the problem, not the other way around.
The cost_usd field, the calibration plot, the committed benchmark, and the cautions.md document are not features of this specific prototype. They are artifacts that any production AI program in a regulated clinical environment needs to produce before a model reaches a patient. This prototype demonstrates what it looks like when those artifacts are treated as first-class deliverables rather than afterthoughts.
Right Tool for the Right Problem
Billy Beane did not win because he had better statisticians than everyone else. He won because he asked a more precise question: which metric actually predicts runs? Once you ask the precise question, the right model becomes obvious.
The right question for 30-day hospital readmission prediction is not "can an AI do this?" Every AI can do this. The right question is: which model produces a calibrated probability in 15 milliseconds with auditable feature attribution and a reproducible benchmark that a medical director can review before it touches a patient workflow?
That question has a clear answer. It is in the repository at github.com/paullopez-ai/readmission-risk-scorer. The benchmark is committed. The cautions are documented. The model is not the impressive one. It is the right one.