AWS Closes Prior Auth Production Gaps with ECS Architecture
Moving from Vercel's stateless serverless to AWS ECS gives AI healthcare apps the persistent memory they need for OAuth caching and HIPAA compliance.
Prior Auth Radar in Production: How AWS Closes the Three Gaps
The AWS architecture that resolves the OAuth cache problem, adds schema validation, and builds a HIPAA-ready audit trail for AI-generated clinical recommendations.
Atul Gawande's The Checklist Manifesto makes a simple argument: expert capability without documented process is unreliable by design. The checklist is not a critique of the surgeon's competence. It is what makes the surgeon's capability consistently executable under pressure. Every hospital knows this. Most software deployments have forgotten it.
The prior authorization radar built in previous articles has three gaps in its pre-flight checklist. The OAuth token cache breaks silently in Vercel's serverless environment, burning an API round-trip on every request. There is no schema validation on Claude's JSON output, risking silent data corruption in clinical dashboards. There is no audit trail for AI-generated clinical recommendations, creating a compliance gap that blocks real healthcare deployments.
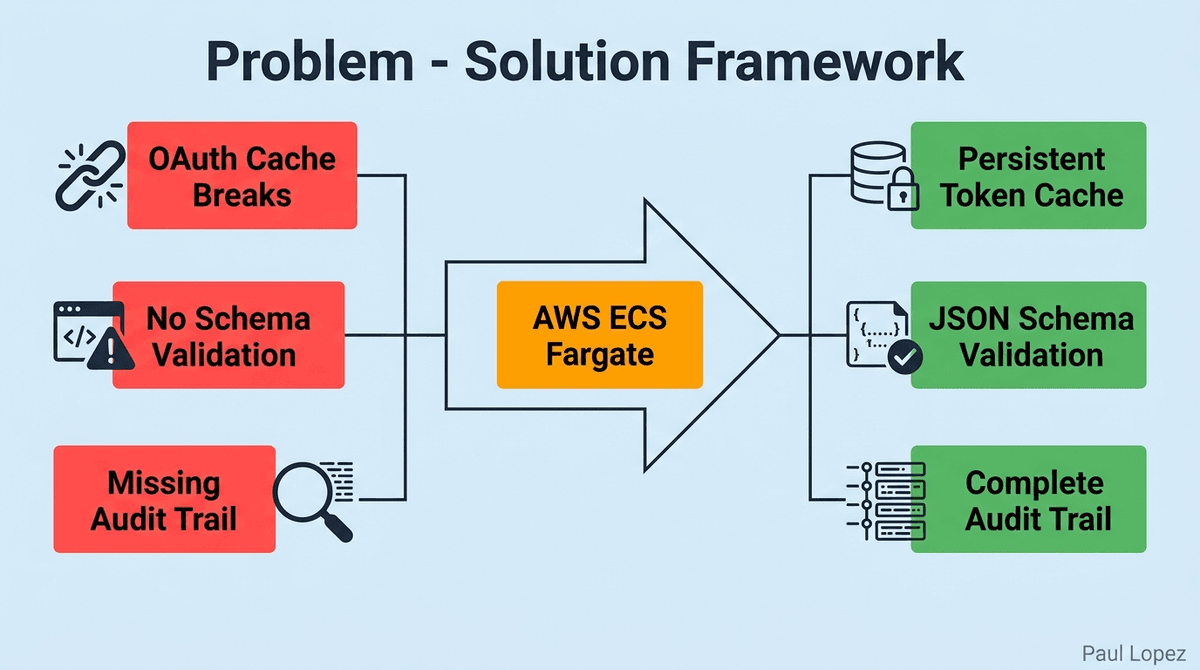
The architectural pivot that enables all three resolutions is a single infrastructure decision: moving from Vercel serverless functions to AWS ECS Fargate. Everything else follows from that choice.
The Architectural Pivot: Why ECS Fargate Changes Everything
Vercel serverless functions are stateless by design. Each function invocation is an independent execution context. Module scope does not persist between requests. This is the right trade-off for most web applications where horizontal scale and zero operational overhead matter more than in-memory state.
It is the wrong trade-off for an application whose OAuth token cache is deliberately stored in module scope.
The token caching logic in lib/optum-auth.ts was correctly implemented. It checks for a cached token, verifies expiry with a sixty-second safety margin, and only calls the Optum identity endpoint when the cache is empty or stale. In a long-running server process, this logic works exactly as designed. In a Vercel serverless function, the module never lives long enough to cache anything. Every invocation is a cold start. Every refresh triggers a fresh OAuth round-trip.
ECS Fargate runs a container. A container is a long-running process. Module scope persists. The token cache works. No Redis dependency required, no code changes to optum-auth.ts, no distributed cache to operate. The fix for Gap 1 is not in the application code. It is in the deployment target.
The move to ECS Fargate solves more than just token caching. HIPAA posture drives the infrastructure decision for any application targeting clinical environments. ECS Fargate is a HIPAA eligible AWS service. When you deploy a healthcare AI application handling PHI-adjacent data, the infrastructure needs to be covered by a Business Associate Agreement. Vercel does not have a HIPAA BAA. AWS does. That single fact would drive the infrastructure decision regardless of the token cache issue.
Predictable latency matters for clinical users in ways most SaaS applications never encounter. Serverless cold starts add 200ms to 2 seconds of latency on the first request after idle. For a dashboard a physician opens when a prior authorization needs action, that cold start delay is unacceptable. ECS Fargate with a minimum task count of 1 stays warm and delivers consistent sub-200ms server response times.
The move to ECS Fargate requires two changes to the application codebase. Adding output: 'standalone' to next.config.ts enables Next.js's Docker-optimized build. Adding a Dockerfile builds the container image. Both are one-line changes. The rest of the ECS configuration lives in infrastructure as code.
The AWS Architecture
The production architecture has four layers. Each layer maps to a specific concern.
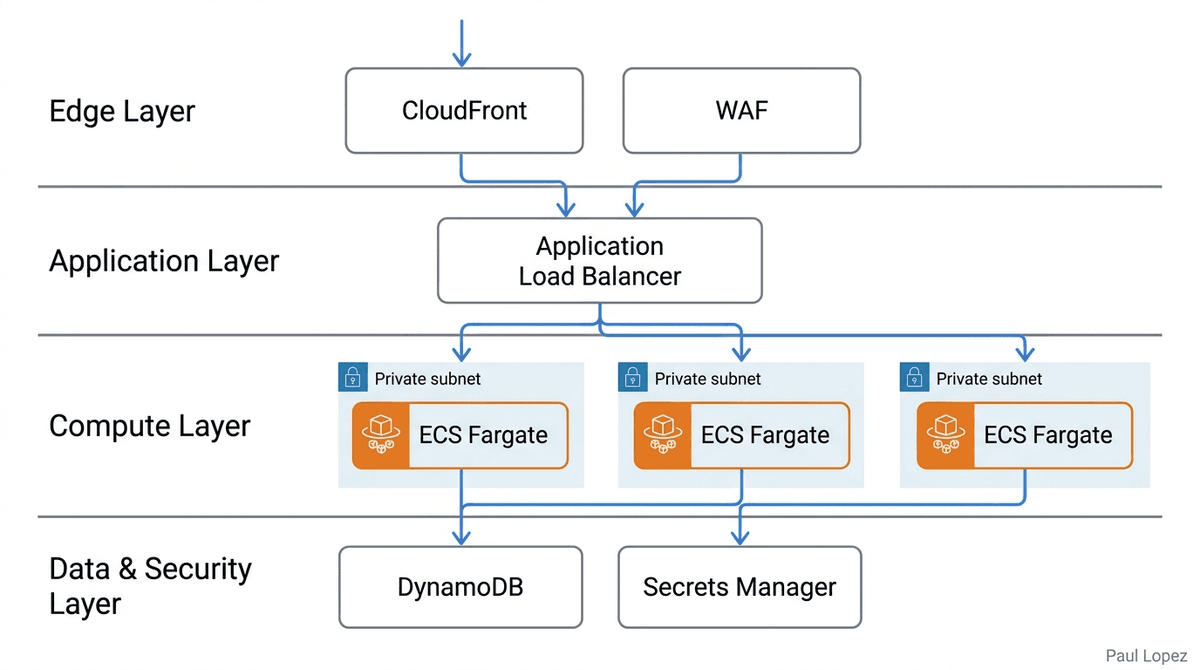
At the edge: CloudFront with WAF. CloudFront terminates HTTPS and serves as the CDN. The WAF layer applies rate limiting per IP (which protects the Anthropic API quota from abuse through the dashboard), the OWASP Core Rule Set for web application protection, and custom rules for healthcare API endpoint patterns. CloudFront's integration with AWS Shield Standard provides baseline DDoS protection at no additional cost.
At the application layer: an Application Load Balancer in public subnets routes to ECS Fargate tasks in private subnets. The ECS task runs the Next.js standalone container. The task definition mounts no persistent volumes; all state lives either in module scope (the OAuth cache) or in DynamoDB (the audit trail). The ECS task role carries a least-privilege IAM policy: read access to specific Secrets Manager ARNs, write access to the audit DynamoDB table, and write access to CloudWatch Logs. No other permissions.
At the data layer: DynamoDB holds the audit trail. The table uses KMS encryption at rest with an AWS managed key. A VPC endpoint for DynamoDB means audit log writes never traverse the public internet. DynamoDB Streams are enabled for future analytics without requiring changes to the application write path. The table's TTL attribute is set seven years from the write timestamp, satisfying the six-year minimum HIPAA retention requirement with a one-year buffer.
At the secrets layer: AWS Secrets Manager replaces .env.local. The four production secrets, the Anthropic API key, the Optum client credentials, the session signing secret, and the password hash, are stored as individual secrets under a path convention of /pa-radar/prod/. At container startup the application fetches these once via the SDK and populates the equivalent of process.env. The IAM policy grants GetSecretValue only on those four specific ARNs. Rotation policies can be attached per secret independently.
Internet
│
▼
CloudFront + WAF (HTTPS termination, rate limiting, OWASP rules)
│
▼
Application Load Balancer (public subnet, us-east-1a / us-east-1b)
│
▼
ECS Fargate Task (private subnet)
├── Next.js Standalone Container
│ ├── lib/optum-auth.ts ← module-scope token cache WORKS (Gap 1 resolved)
│ ├── lib/claude-pa-analyzer.ts + Zod validation (Gap 2 resolved)
│ └── lib/audit-logger.ts → DynamoDB write (Gap 3 resolved)
│
├── Secrets Manager ← replaces .env.local
│ ├── /pa-radar/prod/anthropic-api-key
│ ├── /pa-radar/prod/optum-credentials
│ └── /pa-radar/prod/auth-secret
│
└── DynamoDB: pa-recommendations-audit (KMS encrypted, 7-year TTL)
└── VPC Endpoint (writes never leave AWS network)
Outbound (via NAT Gateway):
└── Optum Real API (idx.linkhealth.com, sandbox-apigw.optum.com)
└── Anthropic API (api.anthropic.com)
Gap 2 Resolved: The Zod Validation Layer
The application already has TypeScript types for every field Claude returns: ClaudePAAction, ClaudePAOutcomePrediction, and ClaudePASummary are defined in types/claude.types.ts. TypeScript enforces these types at compile time. It cannot enforce them at runtime on data arriving from an external API.
Zod is the runtime enforcement layer TypeScript cannot provide. The production fix adds a lib/claude-schema.ts file that defines Zod schemas mirroring the three Claude output types. After analyzeWithClaude() receives and JSON-parses Claude's response, it passes the result through ClaudeAnalysisSchema.safeParse() before returning.
The safeParse path has three outcomes. If parsing succeeds, the validated data proceeds to the dashboard unchanged. If parsing fails on a non-critical field, the schema replaces the invalid value with a defined safe fallback, logs the field name and raw value to CloudWatch Logs, and allows the dashboard to render with a visible degradation indicator rather than a silent missing field. If parsing fails on a critical field, the server falls back to the existing graceful degradation path that builds analysis from raw Optum data.
The CloudWatch Logs entry for a schema failure includes the model version, the field name, the raw value received, and the timestamp. Over time, these entries form an observability dataset: if Claude's output format shifts across a model update, the validation failures surface in CloudWatch before a physician encounters incorrect data.
Gap 3 Resolved: The DynamoDB Audit Trail
The new lib/audit-logger.ts module is called once per successful Claude analysis, immediately after the analysis is assembled and before the API route returns its response. It writes a single DynamoDB item per dashboard refresh.
The audit item structure reflects two HIPAA considerations. First, PHI minimization: the item stores a SHA-256 hash of the input PA data rather than the PA data itself. If a clinician's patient record needs to be reconstructed from the audit trail, the hash provides linkage without storing individually identifiable health information in the audit table. The full PA record remains in the Optum API's own audit systems. Second, provenance completeness: the item records the model version, the system prompt version (a semver string maintained in lib/claude-pa-analyzer.ts), the temperature setting, and the exact timestamp. These four fields together constitute what "Your TOGAF Flight Plan Did Not Survive the AI Oxygen Tank" called Provenance Intelligence: the documented lineage of how the recommendation was produced.
The system prompt version deserves specific mention. When the clinical decision rules in the system prompt change, the version string increments. Every audit item generated before the change carries the old version string; every item generated after carries the new one. This versioning allows a compliance auditor or quality review to distinguish recommendations made under different rule sets without reconstructing the prompt from code history. It is a one-line addition to the application with audit implications that significantly exceed the engineering cost.
The DynamoDB table has Global Secondary Index on modelVersion to support future queries like: show all recommendations generated under model version claude-sonnet-4-6 before the November 2026 model update.
What This Architecture Costs
The cost structure of this architecture has more to teach than the monthly invoice. Three drivers account for the majority of spend at any scale, and understanding them shapes every architectural decision that follows.
The first driver is egress. The NAT Gateway becomes the dominant infrastructure line item not because it is expensive in isolation, but because every request to the Optum Real API and every inference call to the Anthropic API routes through it. In a prototype, this traffic is negligible. In a production deployment serving dozens of clinicians running authorizations across a full patient panel, outbound API volume accumulates fast. Organizations that size this architecture on prototype traffic will be surprised by their first production cloud bill.
The second driver is inference. Claude API token costs scale with two variables most teams underestimate at design time: input context length and request frequency. A prior authorization analysis that passes the full medication history, diagnosis codes, and payer policy context into the prompt can easily consume 8,000 to 12,000 input tokens per request. Multiply that by the authorization volume of a mid-size physician group running 50 to 100 PA requests per day, and token spend becomes a line item that belongs in the architecture conversation, not the operations review after go-live. AWS Bedrock access to Claude models offers consolidated billing and potential enterprise commitment pricing for organizations already running workloads inside AWS, which changes the token cost calculus for larger deployments.
The third driver is the audit trail. DynamoDB on-demand pricing looks negligible for a single practice. It remains manageable at 50 practices. At health system scale, where every AI recommendation across every clinical department writes an audit record, the table becomes a high-volume write workload. The 7-year TTL that satisfies HIPAA retention requirements means the table grows for years before records age out. Point-in-time recovery, KMS encryption, and DynamoDB Streams for downstream analytics each add cost that scales with volume. Sizing the audit trail as an afterthought is an architecture mistake.
The architectural takeaway is not a number. It is a principle: the right question is not what this costs for one practice but what the cost curve looks like as clinical volume and organizational scope grow. An architecture that costs $80 a month for a pilot and $80,000 a month at health system scale with no design changes is not a success story. It is a deferred re-architecture. Building for multi-tenant isolation from the first deployment, designing the audit schema to support partition-key-level cost attribution, and tracking token consumption per request from day one: these decisions cost nothing to make early and a great deal to retrofit later.
The Phase D Decision Made Consciously
The cost breakdown above represents a conscious Phase D technology architecture decision: the living document that tracks infrastructure economics, latency profiles, service limits, and change notification policies before deployment, not after the first cloud bill arrives. The choice of ECS Fargate over Lambda, the NAT Gateway cost as the largest line item, the DynamoDB on-demand pricing at clinical practice write volumes: these are the architectural economics that most enterprise AI programs have never written down. Writing them down before deployment is the discipline Phase D was designed to enforce.
Close
The checklist does not replace the surgeon. It makes the surgeon's capability consistently available to every patient who needs it.
The AWS architecture built here does not replace the AI. It makes the AI's capability trustworthy enough to act on. The OAuth token cache that would have silently degraded under serverless now works as designed. Claude's JSON output now fails loudly on schema violations rather than silently rendering missing data in a clinical dashboard. Every recommendation is now logged with the model version, prompt version, and timestamp that a compliance auditor or clinical reviewer would need to evaluate it.
The three gaps identified at the top of this article were not flaws in the AI capability. They were items missing from the pre-flight checklist. The flight plan was correct. The checklist just needed finishing.
The source code is at github.com/paullopez-ai/prior-auth-radar. The live demo remains at prior-auth-radar.vercel.app.